Context Engineering: Why Your AI Agents Fail in Production (and How to Fix It)
A practitioner's guide to designing what your language model sees on every call — from the write-select-compress-isolate framework and KV-cache economics to retrieval, memory, and security that turn fragile demos into agents that survive the real world.

On this page
- What Context Engineering Actually Is
- The Science: Why a Bigger Context Window Is Not the Answer
- The Four Pillars: Write, Select, Compress, Isolate
- Retrieval Done Right
- Memory Architecture
- Tools and the Model Context Protocol
- Performance and Cost: The KV-Cache North Star
- Evaluation and Observability: Closing the Loop
- Security: The Context Attack Surface
- Putting It Together: A Reference Architecture
- Common Mistakes to Avoid
- Best Practices Checklist
- Where This Is Heading
- A Note on the Terrain
- Key Takeaways
Most agents that reach a demo never survive contact with production. The model is rarely the problem. A team wires up a language model, gives it a few tools, watches it complete a task in a controlled setting, and ships it — only to find that in the real world the agent hallucinates steps, forgets what it was doing, calls the wrong tool, or quietly burns through a budget answering a single question. The reflex is to blame the model and wait for a smarter one. The evidence points somewhere else.
According to the 2025 Stack Overflow Developer Survey, which gathered responses from more than 49,000 developers across 177 countries, 66% report frustration with AI solutions that are "almost right, but not quite." Nearly half — 45% — say that debugging AI-generated code takes longer than writing it themselves, and only 29% trust the accuracy of AI output, down sharply from roughly 43% the year before. Just 3% report "high trust." These are not the numbers of a model-capability problem. They are the signature of a context problem: the agent was handed the wrong information, in the wrong shape, at the wrong moment.
This is the gap that context engineering exists to close. As the freeCodeCamp agent handbook puts it:
"Building a single AI agent... is a solved problem. A handful of tutorials and a few hours of work will get you there. What most tutorials skip is the engineering layer that comes next."
That engineering layer is the subject of this guide.
What Context Engineering Actually Is
Context engineering is the discipline of deliberately designing everything a language model sees on each inference call — the system prompt, retrieved documents, conversation history, tool definitions, memory, and the current query — so that the model has exactly the information it needs to produce a reliable result, and as little else as possible.
The term is young but well-pedigreed. It was popularized in June 2025 by Shopify CEO Tobi Lütke, who described it as "the art of providing all the context for the task to be plausibly solvable by the LLM," and amplified by Andrej Karpathy, who called it:
"The delicate art and science of filling the context window with just the right information for the next step."
Within weeks it acquired academic backing. The July 2025 arXiv survey A Survey of Context Engineering for Large Language Models (arXiv:2507.13334), led by Lingrui Mei and colleagues, reviewed over 1,400 research papers in its second version and defined context engineering as "a formal discipline that transcends simple prompt design to encompass the systematic optimization of information payloads for LLMs." Anthropic and LangChain have since published canonical practitioner guides, with LangChain contributing the now-widely-used "write, select, compress, isolate" taxonomy.
Three nested disciplines
It helps to see context engineering as the middle layer of three concentric skills, each containing the last:
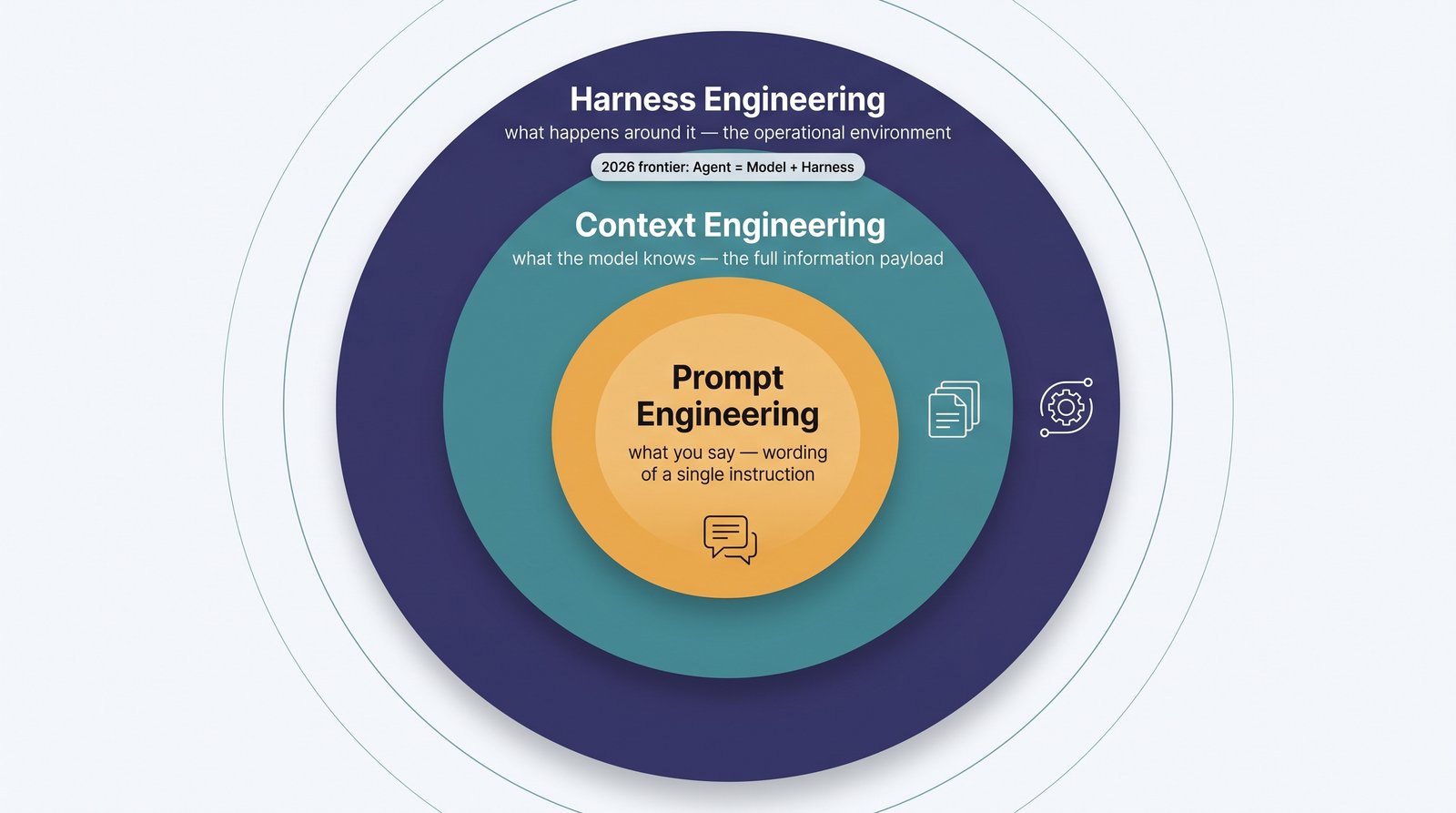
- Prompt engineering — crafting the wording of a single instruction. Concerned with how you phrase the ask.
- Context engineering — assembling the full information payload around that instruction: what to retrieve, what to remember, what tools to expose, what history to keep. Concerned with everything the model sees.
- Harness engineering — designing the entire operational environment in which an autonomous agent runs: control loops, sandboxing, recovery, orchestration. The emerging 2026 frontier, captured in Martin Fowler's framing that "Agent = Model + Harness."
Prompt engineering asks what you say. Context engineering asks what the model knows when you say it. Harness engineering asks what happens around the whole exchange.
A useful mental model: the LLM as a CPU
Think of the language model as a CPU and its context window as RAM — a small, fast, finite working memory. The CPU is powerful, but it can only operate on what is loaded into RAM at the moment of execution. Context engineering is the memory-management discipline for that RAM: deciding what to page in, what to keep resident, what to compress, and what to evict. Dumping your entire knowledge base into the window is the equivalent of loading a terabyte of data into a few gigabytes of memory and expecting it to run smoothly. It will not.
The Science: Why a Bigger Context Window Is Not the Answer
The most common objection to all of this is seductive: if context is the bottleneck, why not just use a model with a million-token window and load everything? The honest answer, grounded in measurement, is that long context windows degrade in ways that make naive stuffing actively harmful.
Chroma's July 2025 technical report, Context Rot: How Increasing Input Tokens Impacts LLM Performance (Kelly Hong, Anton Troynikov, and Jeff Huber), tested this directly. In the authors' own words:
"We evaluate 18 LLMs, including the state-of-the-art GPT-4.1, Claude 4, Gemini 2.5, and Qwen3 models. Our results reveal that models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows."
That single finding dismantles the "just use a bigger window" myth. A model with room for a million tokens does not attend to those tokens evenly. The capacity to hold information is not the same as the capacity to use it well.
Context rot (definition): the measurable decline in a model's reliability as the number of input tokens grows, even when the relevant information is technically present in the window.
Context rot is one of four failure modes that disciplined practitioners design against:
- Context distraction — so much extraneous information surrounds the relevant facts that the model loses the thread of the actual task.
- Context confusion — contradictory or overlapping content (two versions of a document, conflicting instructions) leaves the model unsure which to trust.
- Context poisoning — incorrect, stale, or maliciously injected content enters the window and corrupts the output, sometimes compounding across turns.
- Context rot — the general degradation of attention and accuracy as raw length increases.
The practical upshot, and the foundation for everything that follows: the context window is a scarce, performance-sensitive resource, not free storage. Curating it is not premature optimization. It is the core engineering task.
The Four Pillars: Write, Select, Compress, Isolate
LangChain's taxonomy organizes context-engineering techniques into four operations. Almost every concrete tactic in this guide is an instance of one of them.
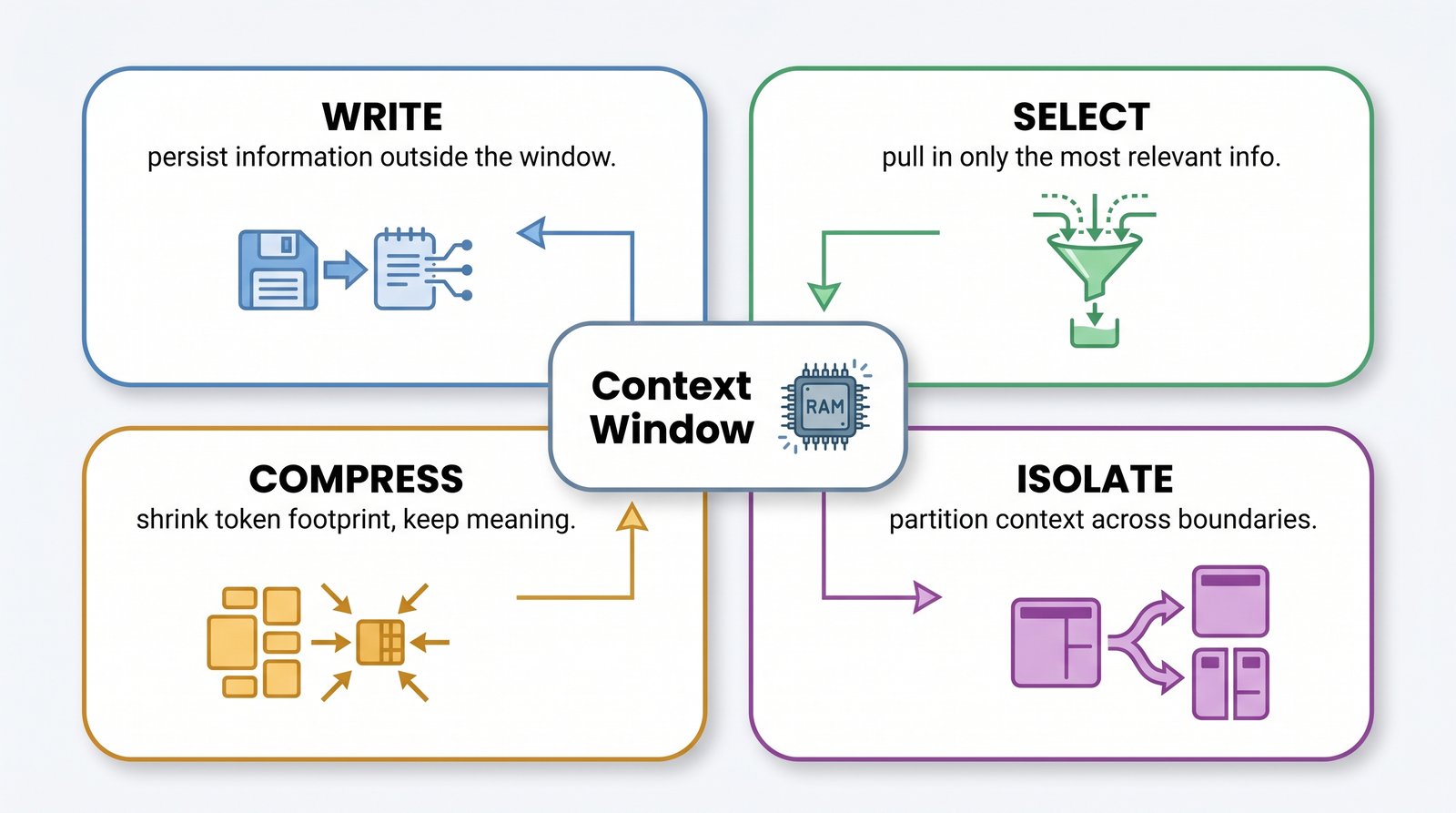
1. Write — persist information outside the immediate context window so it can be recalled later without occupying space now. Scratchpads, to-do files, and external memory stores all live here. The agent writes down what it learned or planned, then reloads only the relevant fragment when needed.
2. Select — pull in only the most relevant information for the current step. This is the home of retrieval (RAG), memory lookup, and tool selection. The discipline is in choosing what to bring in — and, just as importantly, what to leave out.
3. Compress — reduce the token footprint of information while preserving its meaning. Summarizing prior conversation turns, distilling a long document into its essentials, or replacing verbose tool output with a condensed result.
4. Isolate — partition context across boundaries so that unrelated information never collides. Splitting a complex task across specialized sub-agents, each with its own clean context window, is the canonical example.
These four operations act on six types of context, each of which the engineer must budget for explicitly:
- System instructions — the role, rules, and behavioral guardrails.
- User input — the immediate query or command.
- Retrieved documents — knowledge pulled from external sources at runtime.
- Conversation history — the record of the current session.
- Tool definitions — the functions the agent can call and their schemas.
- Long-term memory — durable facts and preferences carried across sessions.
The art, as Anthropic frames it, is finding "the smallest possible set of high-signal tokens" — and writing system prompts at the "right altitude," specific enough to constrain behavior but general enough not to micromanage every case.
Retrieval Done Right
Retrieval-augmented generation (RAG) is the "select" pillar in practice, and most failures here come from treating it as a solved black box. Done carelessly, retrieval becomes a primary source of context distraction and poisoning. Done well, it is the difference between an agent that cites the right policy and one that confidently invents one.
A production-grade retrieval pipeline attends to each of these stages:
- Chunking. How source documents are split determines what can be retrieved. Chunks that are too large dilute relevance and waste tokens; chunks that are too small fracture meaning across boundaries. Chunk along semantic units, not arbitrary character counts.
- Embeddings. The quality of the embedding model governs whether semantically relevant material actually surfaces. A weak embedding model silently caps the ceiling of the whole system.
- Re-ranking. A first-pass vector search optimizes for recall; a re-ranker reorders those candidates for precision. Re-ranking with a hard cap on how many results reach the context window is one of the highest-leverage, most-skipped techniques.
- Just-in-time vs. pre-retrieval. Pre-retrieval loads everything up front; just-in-time retrieval fetches only as the task demands. Hybrid strategies — a small stable base plus targeted on-demand lookups — often win.
Callout — the monorepo cautionary tale: Sourcegraph has described a coding-agent failure where a single
grepacross a million-line monorepo returned roughly 4,000 hits, every one of which flooded into the context window. The retrieval "worked" in the narrow sense of finding matches, and destroyed the agent in the practical sense of burying the signal. The lesson: retrieval without ranking and hard caps is a denial-of-service attack on your own context window.
The governing rule for retrieval is the same as for context generally: enforce hard token caps and prefer precision over volume. More retrieved documents is not more help.
Memory Architecture
Agents that operate over time need to remember — but memory, naively implemented, is just another way to overflow the window. The solution is a deliberate two-tier architecture.
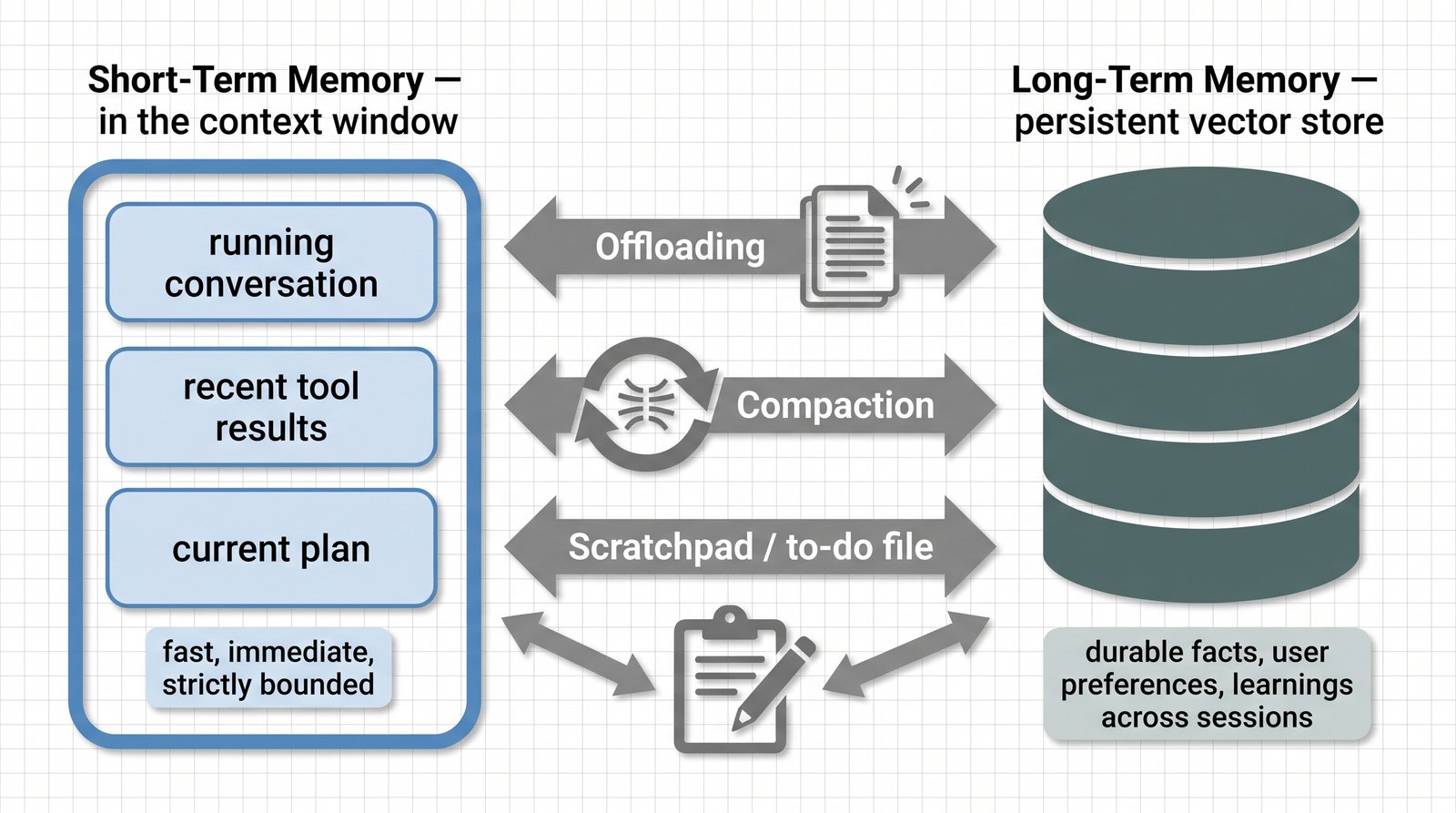
Short-term memory lives in the context window itself: the running conversation, recent tool results, the current plan. It is fast and immediate but strictly bounded.
Long-term memory lives outside the window in a persistent store — typically a vector database — and is selectively retrieved when relevant. It carries durable facts, user preferences, and learnings across sessions without paying for them on every call.
Three patterns make this work in production:
- Offloading. Move information the agent doesn't need right now out of the window and into external storage, retrieving it only when the task calls for it.
- Compaction. Periodically summarize and compress the accumulated history so the window holds a dense digest rather than a verbatim transcript. This directly counteracts context rot as sessions lengthen.
- The scratchpad / to-do-file pattern. The agent maintains an external notes or task file that it writes to and reads from across steps. This keeps its working plan stable and legible even as the conversation grows, and gives it a place to "think" without consuming the window. This is the "write" pillar made concrete.
Tools and the Model Context Protocol
Tools are how agents act on the world, and tool definitions are themselves context — they occupy space and shape behavior. As agents gain capabilities, a predictable problem emerges.
The tool explosion problem: as you add tools, the model's context fills with their definitions and the model grows more likely to choose the wrong one. Beyond a few dozen tools, selection accuracy degrades and the definitions alone can crowd out the actual task. More tools can mean a less capable agent.
The Model Context Protocol (MCP) has emerged as the dominant standard for connecting agents to tools and data sources in a consistent way. Introduced by Anthropic, MCP standardizes how an agent discovers and calls external capabilities, replacing a tangle of bespoke integrations with a common interface. Its adoption has been steep. Per Anthropic's December 2025 ecosystem update, MCP recorded "over 97 million monthly SDK downloads, 10,000 active servers and first-class client support across major AI platforms like ChatGPT, Claude, Cursor, Gemini, Microsoft Copilot, Visual Studio Code" — up from roughly 2 million downloads at its November 2024 launch. The project surpassed 81,000 GitHub stars as of March 2026.
But a standard for connecting tools does not solve the explosion problem. For that, practitioners turn to techniques that constrain which tools are available at any given moment. The team behind Manus AI documented an approach using logit masking driven by a context-aware state machine: rather than physically adding and removing tools mid-session — which, as we'll see, wrecks performance — the agent keeps a stable tool set and masks the model's output probabilities so that only contextually valid tools can be selected at each step. The capability stays present; the availability is gated by state.
Performance and Cost: The KV-Cache North Star
Context engineering is not only about accuracy. It is about latency and cost, and here the single most important lever is the KV-cache hit rate.
The Manus team's widely-cited essay Context Engineering for AI Agents: Lessons from Building Manus (Yichao "Peak" Ji, July 2025) — written after rebuilding their agent framework four times — names it without hedging:
"KV-cache hit rate is the single most important metric for a production-stage AI agent. It directly affects both latency and cost."
The economics are stark. The same post notes that "with Claude Sonnet, for instance, cached input tokens cost 0.30 USD/MTok, while uncached ones cost 3 USD/MTok — a 10x difference." When you consider that Manus reports an input-to-output token ratio of roughly 100:1 — agents read enormously more than they write — it becomes clear that cached input is where the entire cost structure of an agent is won or lost.
Pull quote: Cached input tokens cost a tenth of uncached ones. At a 100:1 read-to-write ratio, KV-cache hit rate isn't an optimization — it's the budget.
Maximizing cache hits comes down to a few disciplined habits:
- Keep prefixes stable. The KV-cache works by reusing computation for identical leading tokens. A single changing character early in the prompt — a timestamp, a session ID, a reordered instruction — invalidates everything after it. Put volatile content at the end, never the beginning.
- Make context append-only. Add to the end of the context; never rewrite or reorder what came before. Every in-place edit is a cache miss cascade.
- Don't add or remove tools mid-session. Beyond confusing the model, mutating the tool list changes the prefix and discards the cache. Use masking (above) instead of mutation.
These are the techniques most tutorials omit entirely, and they are the ones that separate an agent that is affordable at scale from one that quietly bankrupts its own use case.
Evaluation and Observability: Closing the Loop
An agent you cannot observe is an agent you cannot improve. The final discipline of context engineering is building the feedback loop that turns production behavior into measurable, improvable signal.
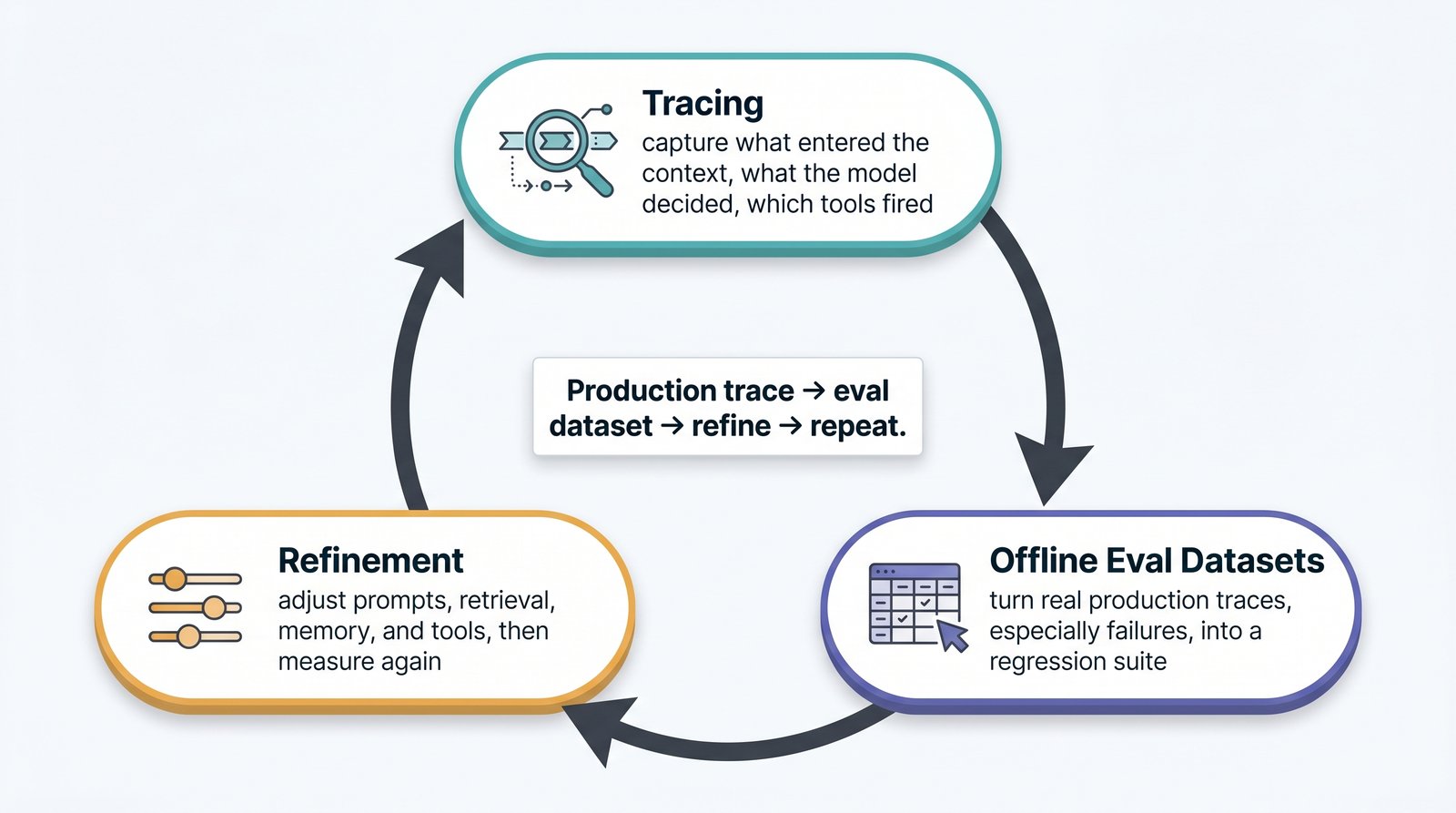
The loop has three stages:
- Tracing. Instrument every agent run so you can see exactly what entered the context window, what the model decided, which tools fired, and what came back. Without tracing, every failure is a mystery.
- Offline evaluation datasets from production traces. Harvest real production traces — especially failures — and turn them into a regression test suite. This grounds your evaluation in what actually goes wrong, not in synthetic cases you imagined.
- Refinement. Use those evaluations to adjust prompts, retrieval, memory, and tool design — then measure again.
A mature tooling ecosystem supports this work, including LangSmith, Langfuse, Comet Opik, Arize, Galileo, and Maxim AI, among others. The specific tool matters less than the commitment to the loop:
Production trace → evaluation dataset → refine → repeat.
This cycle is where context engineering stops being a collection of tips and becomes an engineering practice.
Security: The Context Attack Surface
The moment an agent ingests external content, that content becomes an attack vector. Context is data, and untrusted data can carry instructions.
The OWASP Top 10 for LLM Applications ranks prompt injection (LLM01:2025) as the foremost risk. The principal threats a context engineer must design against:
- Prompt injection. Malicious instructions embedded in user input or external content that hijack the agent's behavior — for example, a web page that tells the agent to ignore its system prompt.
- Tool poisoning. A compromised or malicious tool returns content crafted to manipulate the agent's subsequent decisions.
- RAG poisoning. Adversarial documents planted in the knowledge base so that retrieval itself becomes the delivery mechanism for an attack.
The defense is defense-in-depth: validate and sanitize retrieved and tool-returned content, constrain what tools can do, separate trusted instructions from untrusted data, and never assume that because content is in the context window it is safe to act on. Context poisoning is not only an accuracy bug; it is a security boundary.
Putting It Together: A Reference Architecture
The individual disciplines converge into a single pipeline. A representative production agent stack looks like this:

- Orchestration layer — a framework such as LangGraph manages the agent's control flow, state, and the branching logic of multi-step tasks. LangGraph has become the dominant production orchestration framework, with 126,000+ GitHub stars and named production users including Klarna, LinkedIn, Uber, and Replit.
- Tool layer — MCP provides standardized, governable access to external tools and data, with availability gated by state-aware masking rather than runtime mutation.
- Retrieval layer — semantic chunking, quality embeddings, and re-ranking with hard caps feed only high-signal documents into the window.
- Memory layer — a two-tier design pairs the short-term window with a long-term vector store, mediated by offloading, compaction, and a scratchpad.
- Evaluation layer — tracing and trace-derived eval datasets feed a continuous refinement loop.
The reframe that began this guide is also its organizing principle: every layer exists to put the smallest possible set of high-signal tokens in front of the model at the moment of inference — accurately, affordably, and safely.
Common Mistakes to Avoid
- Dumping everything into the window. "More context is always better" is the central fallacy; context rot guarantees it backfires.
- Treating context engineering as prompt engineering with more words. It is a systems discipline — retrieval, memory, tools, evaluation — not verbose prompting.
- Unstable prompt prefixes. Timestamps, session IDs, or reordered instructions near the top of the prompt silently destroy KV-cache hit rates.
- Mutating the tool list mid-session. It confuses the model and invalidates the cache. Mask instead.
- No evaluation loop, no tracing. Without production observability, you are tuning blind.
- Ignoring the injection surface. Treating retrieved and tool-returned content as trusted is a security failure waiting to happen.
Best Practices Checklist
- Treat the context window as a scarce resource; allocate explicit token budgets per zone (system prompt, dynamic context, current query).
- Pursue "the smallest possible set of high-signal tokens."
- Use re-rankers with hard caps; prefer just-in-time retrieval hybrids.
- Optimize KV-cache hit rate: keep prefixes stable, keep context append-only.
- Build the production-trace → eval-dataset → refine feedback loop.
- Apply defense-in-depth against prompt injection and poisoning.
Where This Is Heading
Context engineering is itself a moving target, and several developments are worth watching through 2026 and beyond. These are trends and predictions, not settled facts:
- Harness engineering as the next layer up. If "Agent = Model + Harness" takes hold, the design focus widens from what the model sees to the entire autonomous operational environment around it — with context engineering as its core sub-discipline.
- Standardized agent memory and multi-agent context sharing, giving agents durable, portable memory and clean protocols for sharing context across specialized sub-agents.
- MCP enterprise maturation — OAuth 2.1, server registries, and convergence with agent-to-agent (A2A) communication standards.
- Context engineering productized for non-developers, abstracting these techniques into tools usable without hand-built pipelines.
A Note on the Terrain
Two honest caveats belong in any serious treatment of this subject.
First, the label is contested. "Context engineering" is roughly a year old. Some practitioners argue it repackages retrieval, information retrieval, and system design under a fashionable name, and there is not yet a standalone encyclopedia entry for it. The competing term harness engineering is already rising for 2026. But the skills — managing a finite attention budget, retrieving precisely, remembering selectively, evaluating continuously — are durable regardless of what the discipline is ultimately called.
Second, many sources carry commercial interests. Vendors who sell retrieval infrastructure, orchestration frameworks, or observability tools have a stake in how these problems are framed. The strongest claims in this guide are anchored to primary, quantified sources — the Chroma 18-model study, the Manus cost economics, the Stack Overflow survey, the academic survey — precisely because the surrounding discourse is noisy. Where figures are cited (GitHub stars, download counts), they reflect specific as-of dates and vary by counting method.
Key Takeaways
- Agents fail in production from bad context, not weak models. Two-thirds of developers struggle with AI that is "almost right" — a context-assembly problem, not a capability ceiling.
- Context engineering is the discipline of designing what the model sees on every call — system prompt, retrieval, memory, tools, history — distinct from prompt engineering and nested inside the emerging field of harness engineering.
- Bigger context windows don't solve it. Measured across 18 models, performance grows less reliable as input length increases. Context rot is real and quantified.
- Four operations organize the work: write, select, compress, isolate — applied across six context types.
- KV-cache hit rate is the cost north star. Cached tokens can cost a tenth of uncached ones, and at a 100:1 read-to-write ratio, that gap defines an agent's entire economics.
- Retrieval, memory, tools, evaluation, and security are one pipeline, not separate buzzwords — and the loop from production traces back to refinement is what makes it an engineering practice rather than a bag of tricks.
The model is rarely the bottleneck. The context is. Engineering it deliberately — accurately, affordably, and securely — is what turns a fragile demo into an agent that survives production.