Large Language Model
From the TaranCodes Wiki
This article is about the AI language system. For the broader field, see Artificial Intelligence.
Contents
- Background and Historical Context
- History and Development
- How It Works
- Types and Categories
- Training Data, Scale and Scaling Laws
- Applications
- Advantages and Limitations
- Comparisons with Alternatives
- Notable Examples and Benchmarks
- Data, Statistics and Trends
- Expert Opinions
- Controversies and Debates
- Legal and Ethical Considerations
- Future Outlook
- Common Misconceptions and Frequently Asked Questions
- Key Takeaways
AI system built on the Transformer that predicts text tokens to generate human language.
A large language model (LLM) is a type of artificial-intelligence system built as a deep neural network and trained on very large quantities of text to model the statistical structure of language. At its core, an LLM learns to predict the next unit of text, called a token, based on the units that came before it. Modern large language models contain hundreds of millions to hundreds of billions of adjustable numerical values known as parameters, and almost all of them are built on the Transformer architecture introduced in 2017. Well-known examples include OpenAI's GPT series, Anthropic's Claude, Google's Gemini and Meta's Llama, which can write text, generate computer code, translate between languages and perform forms of reasoning expressed in natural language.
Large language models belong to the field of natural language processing (NLP), which is the study of how computers handle human language, and they sit within deep learning, a branch of machine learning and the wider field of artificial intelligence. They are often described as a subset of foundation models, a term coined in August 2021 by Stanford University's Institute for Human-Centered Artificial Intelligence (HAI) to describe models trained on broad data at scale that can later be adapted to many specific tasks. LLMs are the language-focused members of this family, which also includes image, audio and multimodal systems.
This article explains what large language models are, how they developed, how they work, their main types and applications, and the benefits, limitations and debates surrounding them. The field has advanced rapidly through scaling, growing from GPT-1's roughly 117 million parameters in 2018 to GPT-3's 175 billion in 2020 and to trillion-parameter multimodal systems by the mid-2020s. As a result, LLMs now sit at the center of both major technological progress and active disputes over understanding, bias, copyright and regulation.
Background and Historical Context
Before neural networks dominated language modeling, the field relied on statistical methods. The earliest widely used approach was the n-gram model, which estimates the probability of the next word from a fixed window of preceding words. The mathematician Claude Shannon discussed n-gram models of English as early as 1951, and such models remained common through the 1990s and 2000s. However, they treated words as isolated symbols with no sense of similarity and struggled with the so-called curse of dimensionality, a problem in which the number of possible word combinations grows too large to handle.
The shift toward neural methods began in 2003, when Yoshua Bengio, Réjean Ducharme, Pascal Vincent and Christian Jauvin at the Université de Montréal published "A Neural Probabilistic Language Model," the first neural language model. Their work learned distributed word representations to address the curse of dimensionality. Building on this, recurrent neural networks (RNNs) and especially Long Short-Term Memory (LSTM) networks, introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997, became standard tools for processing sequences because they could retain information across longer stretches of text.
Word embeddings, which represent words as dense numerical vectors, marked another important step. In 2013, Tomas Mikolov and colleagues at Google released word2vec, which efficiently learned embeddings that captured relationships such as "king minus man plus woman is approximately queen." In 2014, Stanford researchers Jeffrey Pennington, Richard Socher and Christopher Manning released GloVe, which learned embeddings from word co-occurrence statistics. In 2018, the Allen Institute introduced ELMo, which produced contextual embeddings whose values depended on the surrounding sentence. These advances laid the groundwork for the architecture that would define the modern era.
History and Development
The pivotal breakthrough came in 2017 with the paper "Attention Is All You Need," first published on arXiv on June 12, 2017 and presented at the NeurIPS conference later that year. Its eight authors at Google—Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser and Illia Polosukhin—proposed a network architecture based solely on an attention mechanism, removing recurrence and convolutions entirely. Because this design allowed massive parallel training, it made building very large models practical and became the foundation of nearly all later LLMs.
After the Transformer, development split into two main directions. In 2018, Google released BERT (Bidirectional Encoder Representations from Transformers), an encoder-only model trained to fill in masked words and aimed at language understanding tasks. OpenAI took the decoder-only, generative route with its GPT series. GPT-1 in 2018 had about 117 million parameters and demonstrated the value of generative pretraining followed by fine-tuning. GPT-2, released in February 2019, had 1.5 billion parameters and was trained on a 40-gigabyte dataset of web pages called WebText.
GPT-3 followed in 2020 with 175 billion parameters and a 2,048-token context window, showing strong few-shot learning, meaning it could perform tasks from only a few examples. A turning point for public use came through alignment work. InstructGPT in 2022 fine-tuned GPT-3 to follow instructions, and ChatGPT, released on November 30, 2022 and based on GPT-3.5, became the consumer product that triggered widespread adoption. GPT-4 arrived on March 14, 2023 with the ability to accept both text and images, followed by later reasoning-focused models, GPT-4o in 2024 and GPT-5 in 2025. Competing systems soon emerged, including Google's PaLM and Gemini, Anthropic's Claude, Meta's open-weight Llama, France's Mistral, and China's DeepSeek and Qwen.
How It Works
A large language model processes text through several connected stages, beginning with breaking text into tokens. This step, called tokenization, most commonly uses byte-pair encoding (BPE), a method invented by Philip Gage in 1994 for data compression and adapted to language processing by Rico Sennrich, Barry Haddow and Alexandra Birch in 2016. Byte-pair encoding starts from individual characters and repeatedly merges the most frequent adjacent pairs into a fixed vocabulary, which lets the model represent unfamiliar words using known fragments. Each token is then converted into an embedding vector, and position information is added because the attention mechanism does not by itself track word order.
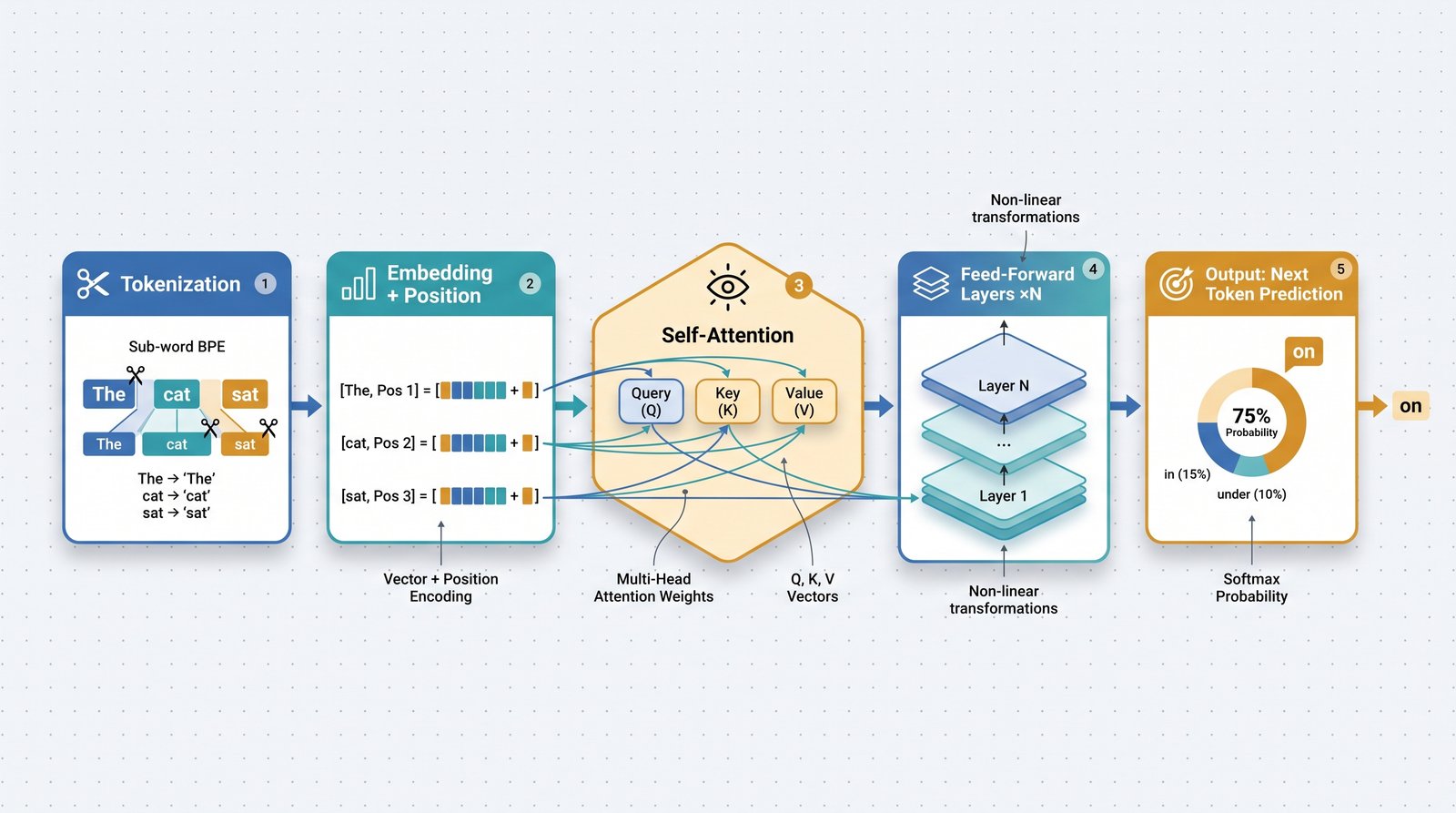
The internal pipeline by which an LLM converts input tokens into a predicted next token.
The core mechanism is self-attention. For each token, the model produces three vectors known as the query, key and value. Attention scores, calculated from the queries and keys, determine how much each token should focus on every other token, and the outputs combine the value vectors accordingly. Multi-head attention performs this process in parallel across several subspaces, allowing different attention heads to capture different relationships, such as the link between a pronoun and the noun it refers to. Stacking many attention and feed-forward layers builds increasingly rich representations of the text.
Training happens in two broad phases. During pretraining, the model learns autoregressively by predicting the next token across trillions of tokens, a self-supervised process that needs no human labels and accounts for the large majority of the total computing cost. Fine-tuning then adapts the base model: supervised fine-tuning uses curated instruction-and-response pairs, after which reinforcement learning from human feedback (RLHF) uses a reward model trained on human preferences to guide the system toward more helpful outputs. According to Long Ouyang and colleagues in their 2022 InstructGPT paper, outputs from the 1.3-billion-parameter InstructGPT model were preferred to those from the 175-billion-parameter GPT-3, showing that careful alignment can outperform raw scale.
Types and Categories
Large language models can be grouped in several ways, the most fundamental being by architecture. Decoder-only or autoregressive models, such as GPT and Llama, form the dominant generative design. Encoder-only or masked models, such as BERT and RoBERTa, are suited to understanding and classification rather than generation. Encoder-decoder models, such as T5 and BART, handle sequence-to-sequence tasks like translation and summarization.
Models also differ by openness. Closed or proprietary models, including GPT-4, Claude and Gemini, do not make their internal weights publicly available, while open-weight models such as Llama, Mistral, DeepSeek, Qwen and Gemma allow their weights to be downloaded. It is worth noting that open-weight, meaning downloadable weights, differs from true open-source, which also includes the code and training data. A further distinction is by tuning stage, separating base models, instruction-tuned models and reasoning models that spend extra computation at the time of use on difficult problems.
Two additional categories are increasingly important. Multimodal LLMs, such as GPT-4o and Gemini, process or generate images, audio or video alongside text. Small language models (SLMs), such as Microsoft's Phi and Google's Gemma, are compact systems optimized for on-device or cost-sensitive use. Some of these rely on a mixture-of-experts (MoE) design, which activates only a fraction of the parameters for each token; for example, DeepSeek-V3 has 671 billion total parameters but uses only about 37 billion at a time.
Training Data, Scale and Scaling Laws
The behavior of large language models depends heavily on the data and scale used to train them. Training corpora are internet-scale mixtures of web text, such as the Common Crawl dataset, along with books, computer code from sources like GitHub, and reference works such as Wikipedia. Parameter counts have grown sharply, from 117 million in GPT-1 to 175 billion in GPT-3 and an estimated one to nearly two trillion in GPT-4, though OpenAI has not confirmed that figure. DeepSeek-V3, by comparison, was pretrained on 14.8 trillion tokens.
Research into scaling laws has shaped how these resources are balanced. The 2020 scaling laws from OpenAI, often linked to Jared Kaplan, found that model loss falls in a predictable power-law pattern as model size, data and compute increase, and suggested that model size should grow faster than data. In 2022, DeepMind's Chinchilla research reversed this conclusion. After training more than 400 models, the team found that model size and training tokens should scale roughly equally, at about 20 tokens per parameter, and that earlier models such as GPT-3 and Gopher were badly undertrained.
The Chinchilla findings had practical consequences. A 70-billion-parameter Chinchilla model trained on 1.4 trillion tokens outperformed the much larger 280-billion-parameter Gopher at equal compute. As a result, smaller models trained on more data are often preferred for deployment because they reduce the cost of running the model. These training runs are nonetheless expensive: according to David Patterson and colleagues in 2021, training GPT-3 produced about 552 tonnes of carbon-dioxide equivalent and consumed 1,287 megawatt-hours of energy, while a separate estimate placed its monetary training cost near 4.6 million US dollars.
Applications
Large language models support a wide range of real-world uses across many industries. The most visible application is conversational assistants and chatbots, including ChatGPT, Claude and Gemini, which respond to questions and instructions in natural language. Closely related are coding assistants such as GitHub Copilot, which help generate, review and refactor software, and increasingly carry out multi-step programming tasks. In search and information retrieval, LLMs are often combined with retrieval-augmented generation (RAG), a method that grounds answers in external documents to improve accuracy.
Beyond these uses, LLMs are widely applied to translation, summarization and content generation, supporting drafting, marketing and general writing. They are also used to automate customer service interactions. In education, they power tutoring features in products such as Khan Academy and Duolingo, helping learners practice and receive explanations.
Other sectors are adopting the technology more cautiously. In healthcare, LLMs assist with clinical documentation and administrative work, though adoption is slower because of compliance and safety requirements. In scientific research, they help synthesize literature, suggest hypotheses and write code for analysis. OpenAI has reported that in workplace settings, writing, research, programming and analysis are the dominant uses, reflecting the broad utility of these systems.
Advantages and Limitations
Large language models offer several notable advantages. A single model can perform a broad range of tasks, interact fluently in natural language, and adapt to new tasks from only a few examples or none at all, without retraining. These qualities can produce strong productivity gains in writing, coding and information synthesis, and the models can be deployed quickly through application programming interfaces (APIs), which let other software access them.
These strengths come with significant limitations. The most discussed is hallucination, the tendency to generate fluent but factually false or unsupported content, which arises from the data, architecture and decoding process; some researchers argue it cannot be fully eliminated. Models also reflect biases present in their training data and can produce unfair or skewed outputs. Because their responses are based on statistical patterns rather than verified knowledge, they lack grounding and can be factually unreliable.
Several further constraints affect practical use. Models have knowledge cutoffs and do not know about events occurring after their training data ends. They also have finite context windows, which limit how much text they can consider at once, although these windows have grown sharply, with some 2025-era models advertising windows of one million tokens. Finally, training and running large models carries substantial computing and energy costs, which raise both financial and environmental concerns.
Comparisons with Alternatives
Comparing large language models with earlier or competing approaches clarifies their strengths and weaknesses. Compared with rule-based or traditional NLP systems, LLMs generalize across many tasks without hand-written rules or task-specific labeled data, but they are less transparent and harder to predict. Compared with search engines, LLMs produce fluent synthesized answers yet may fabricate information, whereas search returns sourced documents; hybrid retrieval-augmented systems aim to combine the benefits of both.
Two further comparisons are often raised. In contrast with symbolic AI, which offers explicit reasoning and verifiable steps, LLMs provide flexible pattern recognition but weak guarantees, motivating neuro-symbolic hybrids that blend the two. Compared with smaller fine-tuned models, task-specific systems can match or exceed LLMs on narrow tasks at lower cost, while LLMs win on breadth and rapid prototyping. These trade-offs explain why organizations often use a mix of approaches rather than a single one.
Notable Examples and Benchmarks
Several model families illustrate the range of current large language models. GPT-4, released by OpenAI in 2023, scored in roughly the top 10 percent on a simulated Uniform Bar Exam, a figure later contested by independent analysis of the percentile method, and reached about 86 percent on the MMLU benchmark. Anthropic's Claude family is aligned using RLHF, with Claude 3.5 Sonnet reaching about 88.7 percent on MMLU. Google DeepMind's Gemini is natively multimodal across text, images, audio, video and code, while Meta's Llama leads open-weight models, with Llama 3.1 405B reaching about 89 percent on MMLU.
Benchmarks provide a common way to measure progress. The Massive Multitask Language Understanding (MMLU) test covers 57 subjects and serves as a standard knowledge measure. Scores rose from 43.9 percent for GPT-3 in 2020 to about 86 percent for GPT-4 in 2023, with top models clustering between 88 and 93 percent by 2024, approaching the human-expert baseline of about 89.8 percent. Because scores were "saturating" and an estimated 6.5 percent of questions were found to contain errors, harder successors such as MMLU-Pro, which uses ten options and graduate-level questions, were created in response.
Data, Statistics and Trends
Quantitative trends show how quickly the field has grown. ChatGPT reached about 100 million monthly active users in January 2023, only two months after launch; a UBS study reported by Reuters described it as the fastest ramp in a consumer internet application the analysts could recall. OpenAI later reported 400 million weekly users in February 2025 and 700 million in July 2025, and chief executive Sam Altman stated at OpenAI DevDay on October 6, 2025 that more than 800 million people use ChatGPT every week.
Other trends concern capability, scale and cost. Benchmark scores on MMLU rose from about 44 percent in 2020 to more than 90 percent by 2025 before leveling off, while parameter counts grew about a thousandfold from GPT-1 in 2018 to GPT-3 in 2020, and training data moved into the trillions of tokens. On energy, GPT-3 training used roughly 1,287 megawatt-hours, and GPT-4 training energy has been estimated at between 51,772 and 62,318 megawatt-hours by Huang and colleagues, while ChatGPT water use has been estimated at about 500 millilitres per short query session. Market forecasts for generative AI vary widely among analysts, with several projecting growth to a few hundred billion dollars by the early 2030s. These market and energy figures are analyst estimates and should be treated as indicative rather than precise.
Expert Opinions
Leading researchers hold sharply differing views on large language models. Geoffrey Hinton, a 2018 Turing Award winner and 2024 Nobel laureate in Physics, left Google in 2023 to warn about serious risks of the technology, citing both existential and labor concerns. Yoshua Bengio, also a Turing Award winner, co-authored 2024 work in the journal Science on managing extreme AI risks and emphasizes reducing catastrophic risk. In contrast, Yann LeCun, Meta's chief AI scientist and a Turing Award winner, argues that current autoregressive LLMs lack genuine understanding of the world and dismisses near-term existential-risk narratives, favoring open models and what he calls world models.
Other prominent voices add further perspectives. The linguist Emily Bender, a co-author of the 2021 "stochastic parrots" paper, argues that LLMs manipulate linguistic form without grasping meaning. Sam Altman, OpenAI's chief executive, champions continued scaling and rapid deployment toward more capable systems. Demis Hassabis, the chief executive of DeepMind, has estimated roughly a 50 percent chance of reaching artificial general intelligence within five years of his remarks, defining such intelligence as matching all cognitive functions of the human brain. These contrasting positions show that experts agree the technology is significant but disagree on its risks and trajectory.
Controversies and Debates
Large language models are the subject of several active debates. One concerns the "stochastic parrots" argument, set out by Emily Bender, Timnit Gebru, Angelina McMillan-Major and a co-author writing as Shmargaret Shmitchell in 2021, which held that LLMs assemble linguistic forms without reference to meaning and flagged environmental, bias and deception risks. The paper became central to Timnit Gebru's departure from Google, and some critics described it as advocacy rather than research.
Another debate concerns emergent abilities, meaning skills that appear suddenly as models grow. Rylan Schaeffer, Brando Miranda and Sanmi Koyejo argued in 2023 that many such abilities are largely artifacts of the metrics used, and that switching to continuous measures reveals smooth, predictable improvement instead. Further disputes surround whether scaling leads to general intelligence, alongside contested concerns over copyright, environmental impact, job displacement and misinformation. Together these debates show that both the capabilities and the wider effects of LLMs remain unsettled.
Legal and Ethical Considerations
Legal and regulatory frameworks for large language models are forming in real time. A prominent case is The New York Times v. OpenAI and Microsoft, filed on December 27, 2023 in the Southern District of New York, which alleges mass copyright infringement; in March 2025, Judge Sidney Stein allowed core infringement claims to proceed while narrowing the case. OpenAI argues that its use of text is fair and transformative. Related lawsuits include authors' cases brought by Paul Tremblay and Sarah Silverman, and two 2025 rulings, Bartz v. Anthropic and Kadrey v. Meta, found model training to be highly transformative.
Regulation is also taking shape, most notably through the European Union's AI Act, which entered into force on August 1, 2024. Obligations for providers of general-purpose AI models applied from August 2, 2025 and include transparency, summaries of training data and copyright policies, with stricter rules for models judged to pose systemic risk, presumed above a training-compute threshold of 10 to the power of 25 floating-point operations. Enforcement powers apply from August 2, 2026, and pre-existing models have until August 2, 2027 to comply. Alongside these legal questions, data privacy, fairness and safety methods such as RLHF, red-teaming and evaluation remain central governance themes.
Future Outlook
Several research directions are shaping the future of large language models. One is the development of reasoning models that use additional computation at the time of use to work through hard problems. Another is the rise of agents that can plan and use external tools over longer sequences of steps. Researchers are also pursuing deeper multimodality and greater efficiency through techniques such as mixture-of-experts designs, distillation and quantization, which aim to produce smaller, high-quality models.
A broader debate concerns whether continued scaling will keep paying off or reach its limits. Demis Hassabis and others foresee possible artificial general intelligence around 2030, while Yann LeCun argues that a new paradigm beyond autoregressive LLMs, based on world models, will be needed. At the same time, the saturation of existing benchmarks is pushing the field toward harder evaluations. As a result, the coming years are likely to bring both technical change and continued disagreement about the destination.
Common Misconceptions and Frequently Asked Questions
Several common misunderstandings surround large language models. A frequent question is whether LLMs truly "understand" language. This remains contested: the models capture statistical relationships in text, and while critics describe this as form without meaning, others point to their sophisticated functional abilities, with no consensus reached. Another common question is whether LLMs are conscious; there is no evidence supporting consciousness, and it is not a mainstream scientific claim.
Two further questions concern how the models handle text and how they relate to AI generally. People often ask whether LLMs store or copy text directly. In fact, they store learned weights rather than a database of documents, although they can sometimes memorize and reproduce training passages word for word, a point central to copyright disputes. Finally, an LLM is not the same as artificial intelligence as a whole; it is one type of AI system, while AI is a far broader field.
Key Takeaways
Large language models are deep neural networks, almost always based on the 2017 Transformer architecture, that learn to predict the next token across enormous text corpora and power systems such as GPT, Claude, Gemini and Llama. Their capabilities advanced rapidly through scaling, supported by alignment methods such as instruction tuning and RLHF that turned raw predictors into usable assistants. This progress drove extraordinary adoption, with ChatGPT reaching hundreds of millions of users within a few years.
At the same time, LLMs remain flawed and contested. They hallucinate, reflect bias, lack grounding and consume significant energy, and they sit at the center of unresolved debates over understanding, emergent abilities, copyright and AI risk. Understanding both their strengths and their limitations is essential for using them responsibly as the technology and its surrounding rules continue to evolve.
References
- "Attention Is All You Need" (Vaswani et al., 2017), arXiv
- "A Neural Probabilistic Language Model" (Bengio et al., 2003), JMLR
- "Training language models to follow instructions with human feedback" (Ouyang et al., 2022), arXiv
- "Are Emergent Abilities of Large Language Models a Mirage?" (Schaeffer, Miranda, Koyejo, 2023), arXiv
- "Carbon Emissions and Large Neural Network Training" (Patterson et al., 2021), arXiv
- "A Survey of Safety and Trustworthiness of Large Language Models" (Huang et al.), arXiv
- Reuters – ChatGPT fastest-growing consumer app (UBS study)
See also
- Context Engineering — Context Engineering is an AI discipline for curating LLM inputs, emerging in mid-2025.
Last updated on June 16, 2026.