Apache Iceberg: The Complete Production Lakehouse Guide
How the open table format won the data wars—and how to build, operate, and scale a lakehouse on top of it

On this page
- 1. Introduction: Why the Lakehouse Won
- From Warehouses and Lakes to the Lakehouse
- The Problem with Hive-Style Tables
- What "Open" Actually Buys You (and What It Doesn't)
- 2. Iceberg Fundamentals
- The Three Layers: Format, Catalog, Engine
- The Metadata Tree: Metadata File, Manifest List, Manifests, Data Files
- Snapshots, ACID, and Optimistic Concurrency
- Schema Evolution and Hidden Partitioning
- 3. Hands-On: Your First Iceberg Table
- Local Setup (Spark + a REST Catalog + MinIO/S3)
- Creating, Writing, and Querying a Table
- Time Travel and Rollback in Practice
- Evolving Schema and Partitioning Without Rewrites
- 4. The V2 → V3 Leap
- Copy-on-Write vs. Merge-on-Read
- Deletion Vectors and Faster Deletes/Updates
- Row Lineage for CDC and Audit
- VARIANT, Geospatial, and Nanosecond Types
- Engine Support Reality Check (Who Supports V3 Today)
- 5. Choosing a Catalog
- Why Iceberg Requires a Catalog
- Apache Polaris, Unity Catalog, Glue, Nessie, Lakekeeper
- The REST Catalog Spec and Credential Vending
- Avoiding Catalog Lock-In
- 6. Managed vs. Self-Managed
- Amazon S3 Tables: The Fully Managed Path
- Self-Managed Iceberg on S3 + Glue
- Cost, Performance, and Operational Trade-offs
- 7. Operating Iceberg in Production
- The Small-File Problem and Compaction Strategies
- Snapshot Expiration and Orphan-File Cleanup
- Performance Tuning: Sort Orders, Z-Ordering, Write Distribution
- Observability and Cost Control
- 8. Migration Patterns
- In-Place vs. Shadow Migration from Hive/Parquet
- Incremental and CDC Ingestion (Kafka/Flink → Iceberg)
- Multi-Engine Rollout
- 9. The Lakehouse as AI Foundation
- Serving Analytics, ML, and Agentic Workloads from One Copy
- Storing Embeddings and Unstructured Data Alongside Tables
- 10. The Road Ahead: Iceberg V4 and Format Convergence
- Real-World Case Studies
- Tools, Frameworks, and Platforms
- Common Mistakes to Avoid
- Best Practices Checklist
- How Iceberg Became the Standard
- Frequently Asked Questions
- Key Takeaways
- Sources
The lakehouse has quietly become the default way large organizations store and analyze data. What started as an ambitious idea—combining the cheap, flexible storage of a data lake with the reliability and performance of a data warehouse—is now the operating model for most enterprises. And at the center of this shift sits a single open technology that nearly every major data vendor has agreed to standardize on: Apache Iceberg.
This guide explains what Iceberg is, how it works, why it won the race to become the industry's open table format, and how to build and operate a production lakehouse on top of it. It is written for engineers and architects who want more than a surface-level overview—covering the fundamentals, a hands-on starting point, the newest features in the V3 specification, the all-important catalog decision, and the operational realities of running Iceberg at scale.
1. Introduction: Why the Lakehouse Won
From Warehouses and Lakes to the Lakehouse
For years, data teams faced an awkward choice. Data warehouses offered fast queries, reliable transactions, and strong governance—but they were expensive and locked your data inside a proprietary system. Data lakes flipped the trade-off: cheap object storage that could hold anything, but with weak guarantees around consistency, correctness, and performance.
The lakehouse emerged to end this compromise. It keeps data in open file formats on inexpensive cloud object storage, while adding the transactional reliability, schema management, and query performance people expected from a warehouse. The result is one copy of data that can serve business intelligence, machine learning, and everything in between.
This is no longer a fringe pattern. According to MIT Technology Review Insights (2023), 74% of global CIOs report having a lakehouse in their estate, with almost all of the remainder planning to adopt one within three years. The lakehouse has moved from promise to default.
The Problem with Hive-Style Tables
To understand why Iceberg matters, you need to understand what came before it. For a long time, "tables" on a data lake were really just directories of files, organized using conventions inherited from Apache Hive. A table was a folder, partitions were subfolders, and the query engine figured out which files to read by listing directories.
This approach was fragile. Listing millions of files was slow. There were no real transactions, so a failed write could leave a table in a corrupted, half-updated state. Changing how a table was partitioned often meant rewriting the entire dataset. Two jobs writing at the same time could clobber each other's results. The directory was the table, and that made everything brittle.
Iceberg replaces this with an explicit, metadata-driven design. Instead of inferring a table from a folder layout, Iceberg tracks exactly which files belong to a table at any given moment—enabling reliable transactions, instant schema changes, and features that simply weren't possible with Hive-style tables.
What "Open" Actually Buys You (and What It Doesn't)
Iceberg's biggest strategic contribution is format portability. Because it is an open standard governed by the neutral Apache Software Foundation, your data lives in one open copy that many different engines can read and write. Vendors that once pushed proprietary formats now compete on top of the same open data.
But it's important to be precise about what openness delivers:
Format portability is now real and nearly free. Governance and performance portability are not.
In other words, moving your data between engines is easy. But how that data is governed, secured, and optimized still depends heavily on the catalog and engine you choose. This distinction—what's truly portable versus what still ties you to a vendor—is the strategic heart of the modern lakehouse, and a theme we'll return to throughout this guide.
2. Iceberg Fundamentals
The Three Layers: Format, Catalog, Engine
The single most common source of confusion among newcomers is conflating three distinct things. Internalizing this mental model will resolve most of your early questions:
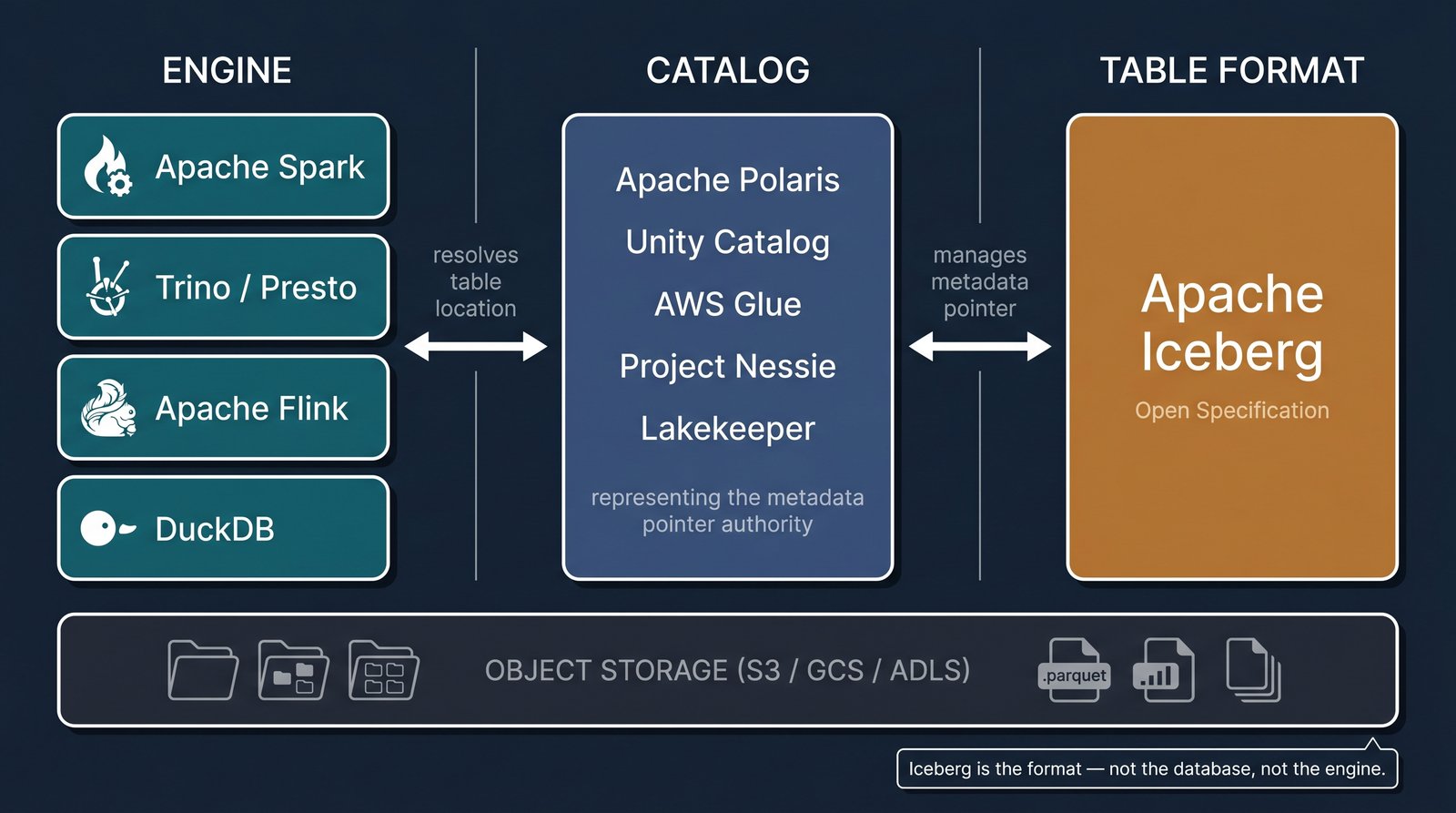
Iceberg is a format, not a database — it requires both a catalog and an engine.
- The table format (Iceberg). This is the open specification that defines how a table's metadata and data files are structured and tracked. Iceberg itself stores nothing and runs no queries—it's a standard.
- The catalog. This is the service that keeps track of where a table's current metadata lives and manages atomic updates to it. Examples include Apache Polaris, Databricks Unity Catalog, AWS Glue, Project Nessie, and Lakekeeper.
- The engine. This is the compute that actually reads and writes data: Apache Spark, Trino/Presto, Apache Flink, DuckDB, and others.
Iceberg is the format. It needs both a catalog to point to it and an engine to process it. Treating Iceberg as if it were a database or a query engine is one of the most frequent and costly misunderstandings.
The Metadata Tree: Metadata File, Manifest List, Manifests, Data Files
Iceberg's reliability comes from a layered metadata tree that sits between the catalog and your raw data files. From top to bottom:
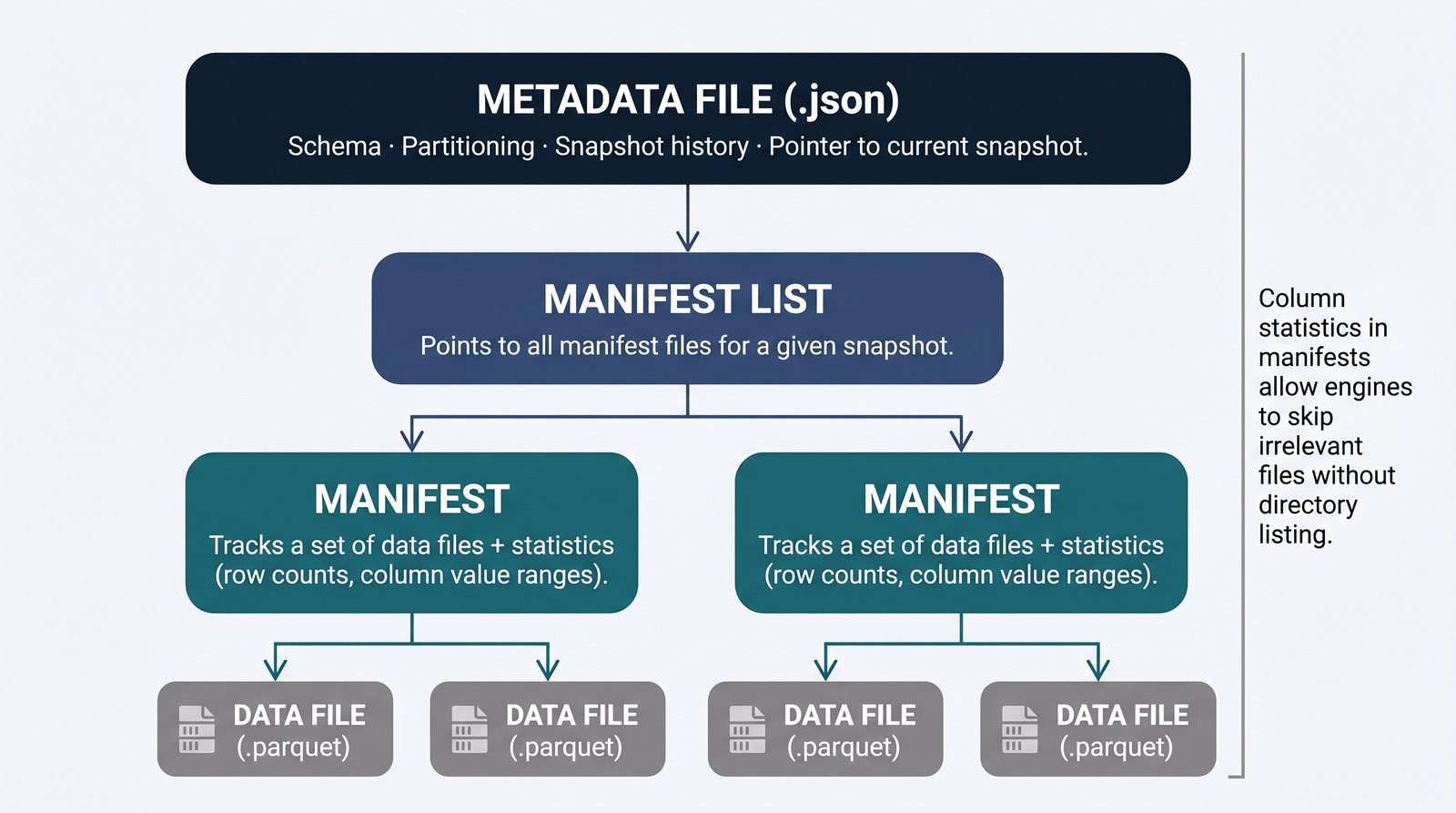
Iceberg's metadata tree lets engines skip irrelevant files without ever listing directories.
- Metadata file. A JSON file describing the table's current state—its schema, partitioning, snapshot history, and a pointer to the current snapshot.
- Manifest list. For a given snapshot, this file points to all the manifest files that make up the table at that moment.
- Manifests. Each manifest tracks a set of data files, along with statistics like row counts and per-column value ranges that let engines skip irrelevant files.
- Data files. The actual data, typically stored as Parquet (or ORC/Avro).
This hierarchy is what makes Iceberg fast and trustworthy. Engines don't need to list directories; they read the metadata tree to know exactly which files matter. The column statistics in manifests enable aggressive file pruning, so queries touch only the data they need.
Snapshots, ACID, and Optimistic Concurrency
Every change to an Iceberg table produces a new snapshot—a complete, immutable view of the table at a point in time. The catalog's job is to atomically swap the pointer from the old metadata file to the new one. Because that swap is a single atomic operation, readers always see a consistent version of the table and never a half-written state.
This is how Iceberg delivers ACID transactions on cheap object storage. It uses optimistic concurrency control: a writer prepares its changes, then attempts to commit by swapping the metadata pointer. If another writer committed first, the commit fails and is retried against the new state. No long-held locks, no corruption.
Snapshots also unlock two beloved features almost for free:
- Time travel. Because old snapshots are retained, you can query the table exactly as it existed at a past point in time.
- Rollback. If a bad batch load corrupts your data, you can roll the table back to a previous snapshot.
Schema Evolution and Hidden Partitioning
Iceberg tracks columns by a stable internal ID, not by name or position. This makes schema evolution safe and metadata-only: you can add, drop, rename, or reorder columns without rewriting a single data file, and without the risk of silently reading the wrong column.
Hidden partitioning is equally powerful. With Hive-style tables, users had to know the physical partitioning scheme and filter on partition columns explicitly, or queries would scan everything. Iceberg records the relationship between a column and its partition values as metadata. Users query naturally—filtering on a timestamp, for example—and Iceberg automatically prunes partitions behind the scenes. Even better, you can evolve the partitioning of a table over time without rewriting old data.
3. Hands-On: Your First Iceberg Table
The fastest way to build intuition is to run Iceberg locally. The goal here is a small, self-contained setup you can experiment with before touching cloud infrastructure.
Local Setup (Spark + a REST Catalog + MinIO/S3)
A typical local stack combines three pieces that mirror the three-layer model:
- Apache Spark as the engine.
- A REST catalog implementation as the catalog.
- MinIO (an S3-compatible object store) standing in for cloud storage.
Spark is the most common starting point because it has the most mature Iceberg support—the 2025 State of the Apache Iceberg Ecosystem survey found Spark in use by 96.4% of respondents, with Trino close behind at 60.7%.
Creating, Writing, and Querying a Table
Once the stack is running, you create a table through standard SQL against your catalog, insert rows, and query them back. Behind each write, Iceberg is generating new data files, new manifests, and a new snapshot—then asking the catalog to atomically swap in the new metadata pointer. The experience feels like an ordinary database, but everything underneath is open files on object storage.
Time Travel and Rollback in Practice
After a few writes, you'll have several snapshots. You can inspect the snapshot history and then query the table as of a specific snapshot or timestamp. This is invaluable for debugging: if a batch job introduces bad data, you can compare versions and, if needed, roll the table back to the last good snapshot—turning what used to be a painful recovery into a single operation.
Evolving Schema and Partitioning Without Rewrites
Finally, add a column, rename one, or change the partition specification, and observe that no data files are rewritten. These operations touch only metadata. Seeing this firsthand is the moment Iceberg's design tends to click: the table is defined by its metadata tree, not by the physical layout of files on disk.
4. The V2 → V3 Leap
Iceberg's specification has evolved through numbered versions. V3 was ratified and rolled out across the 2025 releases (versions 1.8.0 through 1.10.0), and it adds substantial new capabilities. But—and this is critical—engine support for V3 is uneven, a caveat we'll address head-on.
Copy-on-Write vs. Merge-on-Read
To understand V3's improvements, you first need these two strategies for handling updates and deletes:
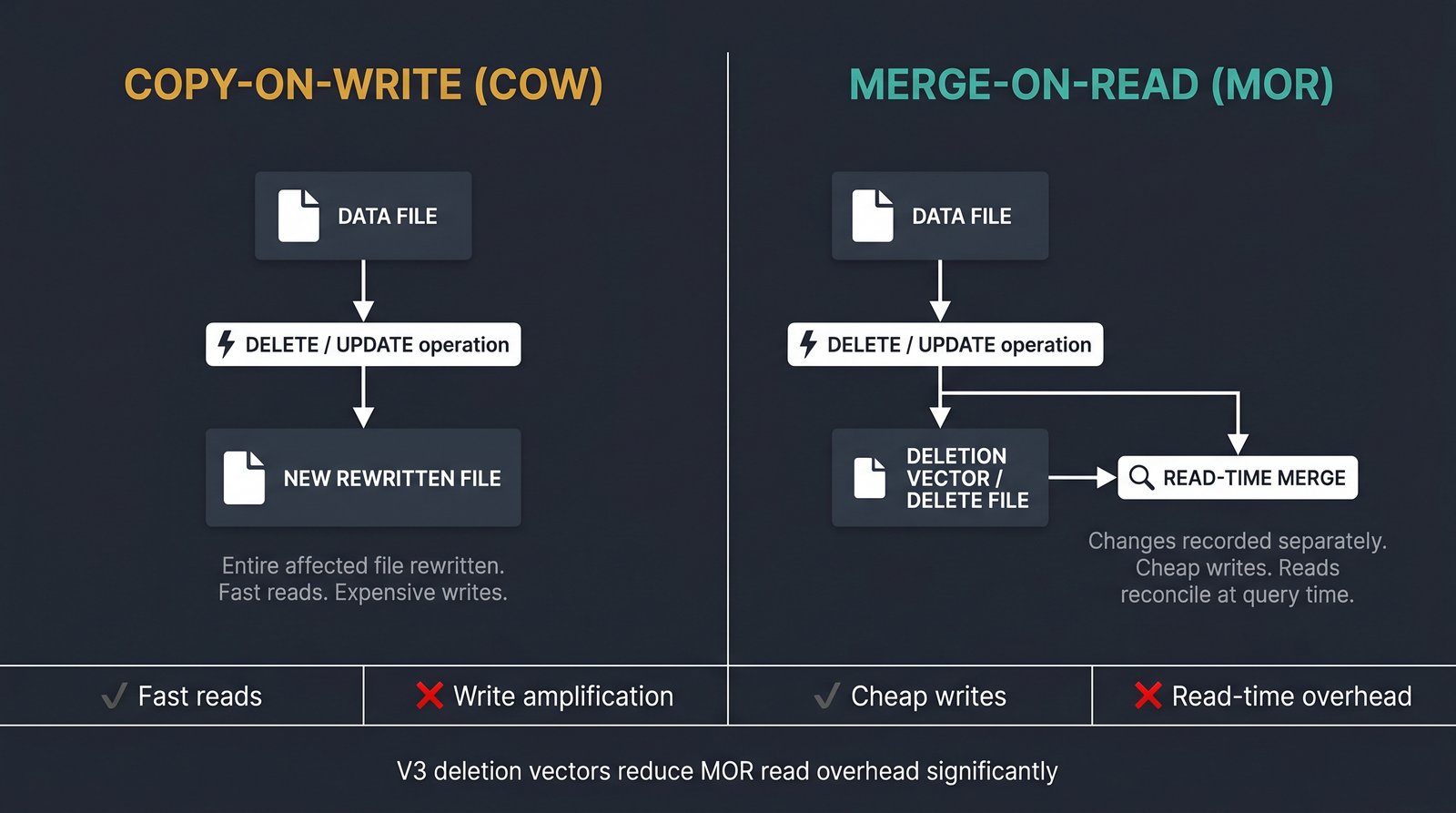
- Copy-on-write (COW). When you modify rows, Iceberg rewrites the entire affected data file with the changes applied. Reads are fast because data is always clean, but writes are expensive—a small delete can trigger a large rewrite.
- Merge-on-read (MOR). Instead of rewriting data, Iceberg records the changes separately (as delete files) and merges them at read time. Writes are cheap, but reads pay a cost to reconcile deletes.
Earlier versions handled MOR deletes using position deletes (marking specific row positions) and equality deletes (matching rows by column values). These worked but added overhead and complexity.
Deletion Vectors and Faster Deletes/Updates
V3 introduces deletion vectors: compact binary bitmaps that mark which rows in a data file have been deleted. They are far more efficient than the older delete-file approaches, reducing both storage overhead and read-time merge cost. This is especially valuable for high-mutation workloads.
A concrete example: handling GDPR "right to be forgotten" requests. Previously, deleting individual records caused heavy write amplification that degraded pipelines. With deletion vectors, compliance deletes become lightweight—you mark rows as deleted without rewriting large files.
Row Lineage for CDC and Audit
V3 adds row lineage through two metadata fields: _row_id and _last_updated_sequence_number. These let you track individual rows as they change over time, which is foundational for change data capture (CDC), incremental processing, and audit use cases. Instead of reprocessing entire tables, downstream systems can identify exactly which rows changed and when.
VARIANT, Geospatial, and Nanosecond Types
V3 also expands Iceberg's type system:
- The VARIANT type stores semi-structured data—like JSON from APIs or event streams—natively, with predicate pushdown. Instead of storing JSON as a string and parsing it at query time, you store it in a VARIANT column and query into it efficiently.
- Geospatial types add first-class support for location data.
- Nanosecond timestamps provide higher temporal precision than the previous microsecond limit.
Engine Support Reality Check (Who Supports V3 Today)
Here is the caveat that any honest treatment of V3 must flag. As of late 2025, support was genuinely uneven:
- Amazon Athena did not yet support V3.
- Trino/Presto were still implementing reader support.
- PyIceberg offered only basic V3 reads.
Adopt V3 selectively. Start with your highest-mutation and most semi-structured tables—after confirming that every engine in your stack supports the features you plan to use.
Engine support is the fastest-moving element of the Iceberg story. Treat any support matrix as a dated snapshot and verify against current engine documentation before committing.
5. Choosing a Catalog
If there's one decision that deserves the most thought, it's the catalog. It is simultaneously the most consequential and the least understood choice in a lakehouse architecture.
Why Iceberg Requires a Catalog
The catalog is what makes Iceberg's atomic commits possible. It holds the authoritative pointer to each table's current metadata file and guarantees that updates to that pointer happen atomically. Without a catalog, there's no safe way for multiple writers to coordinate, and no single source of truth for which version of a table is current.
Apache Polaris, Unity Catalog, Glue, Nessie, Lakekeeper
Several catalog options compete for this role:
- Apache Polaris. Open-sourced by Snowflake and contributed to the Apache Software Foundation, designed around the open REST catalog standard.
- Databricks Unity Catalog. Now available as open source, with native Iceberg support added in June 2025.
- AWS Glue Data Catalog. The default catalog for many AWS-based deployments.
- Project Nessie. Brings Git-like branching and version control semantics to your data.
- Lakekeeper. A newer open REST catalog implementation.
Other entrants like Apache Gravitino are expanding the field further.
The REST Catalog Spec and Credential Vending
A pivotal development is the Iceberg REST catalog specification—a standardized API that any catalog can implement and any engine can speak. This decouples engines from catalogs: as long as both sides speak the REST protocol, they interoperate. The spec also supports credential vending, where the catalog hands out scoped, temporary storage credentials to engines, centralizing access control rather than scattering credentials across clients.
Avoiding Catalog Lock-In
Because the catalog governs security, access, and metadata, it is where vendor lock-in is most likely to creep back in—even though your data format is open. The defensive strategy is to standardize on the Iceberg REST catalog spec. If your catalog and engines all speak the open REST protocol, you preserve the ability to switch components later. The looming "catalog wars" make this discipline more important, not less.
6. Managed vs. Self-Managed
A practical early decision is how much of the operational burden you want to own.
Amazon S3 Tables: The Fully Managed Path
Amazon S3 Tables reached general availability in 2025 and offers fully managed Iceberg storage. AWS handles much of the routine maintenance—compaction and cleanup—automatically. For teams that want the benefits of Iceberg without operating the machinery, this lowers the barrier significantly. If you go this route, verify that automatic maintenance is actually enabled for your tables.
Self-Managed Iceberg on S3 + Glue
The alternative is running Iceberg yourself on general-purpose S3 buckets paired with a catalog like Glue. This gives you maximum control and flexibility over configuration, engine choice, and tuning—at the cost of owning all the operational work: compaction scheduling, snapshot expiration, orphan-file cleanup, and performance tuning.
Cost, Performance, and Operational Trade-offs
The choice comes down to control versus convenience. Managed S3 Tables reduce operational toil and the risk of neglected maintenance, which is a common failure mode. Self-managed setups offer finer control and can be more cost-efficient at scale or for specialized workloads, but only if your team has the expertise to operate them well. There is no universally correct answer—only the right answer for your team's size, skills, and requirements.
A critical safety rule for either path: never use raw, non-Iceberg S3 operations to delete or overwrite files directly. Doing so corrupts the table's metadata state. AWS explicitly warns against this. Always mutate tables through Iceberg-native APIs.
7. Operating Iceberg in Production
This is where the durable, hard-won value lies. Most introductions stop at "what is Iceberg." Running it well in production is a different discipline.
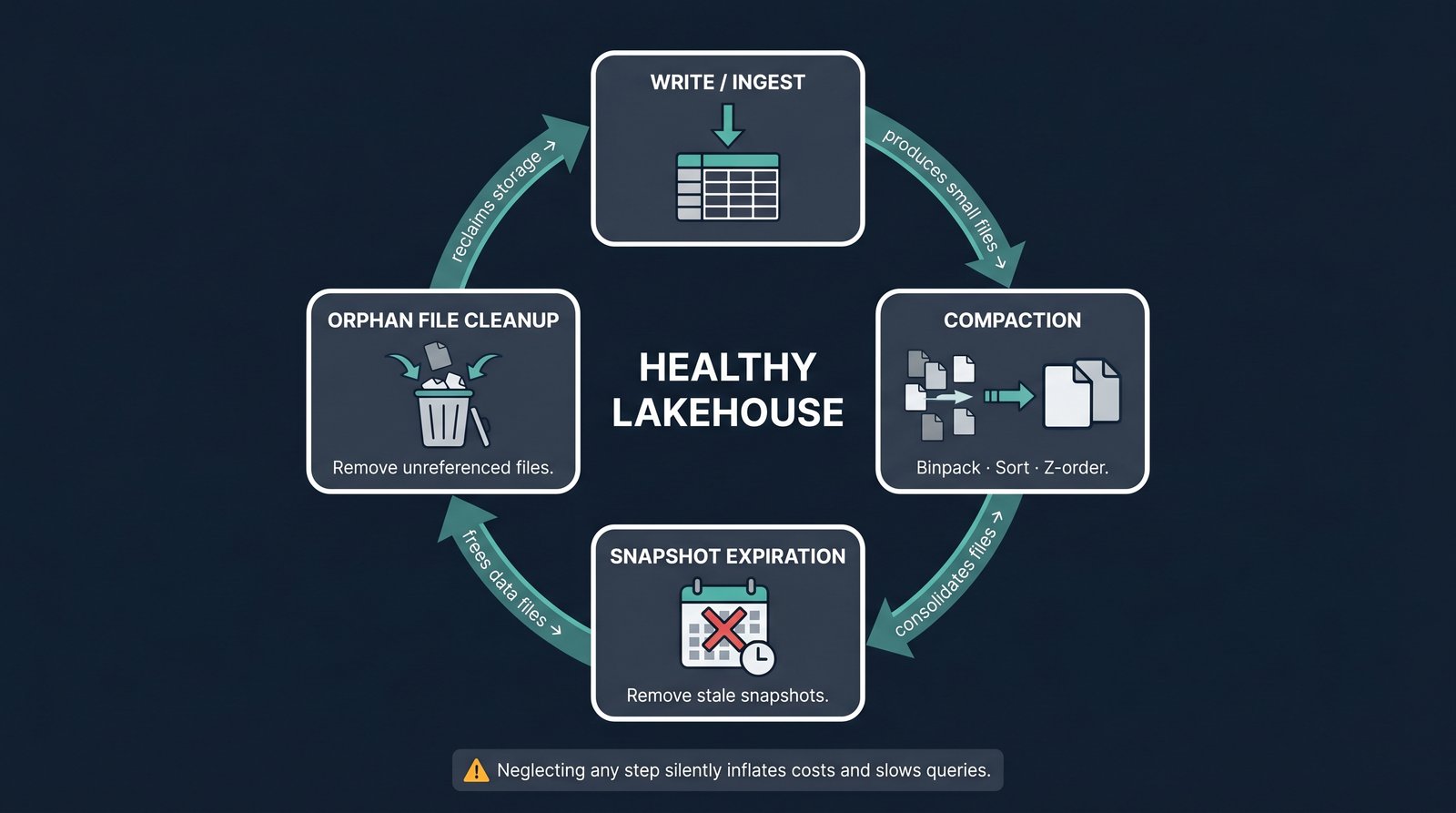
The Small-File Problem and Compaction Strategies
Streaming and frequent writes tend to produce many small files, which slows queries and inflates costs. The remedy is compaction: periodically rewriting small files into fewer, larger ones. Iceberg supports several strategies:
- Binpack. Simply combines small files into larger ones.
- Sort. Reorganizes data by sort keys during compaction.
- Z-order. Clusters data across multiple dimensions for better filtering.
The choice matters. AWS reports 3x or greater scan improvements when switching from binpack to sort or z-order compaction on tables with selective filter columns. For tables frequently filtered on specific columns, the investment in sort or z-order compaction pays off directly in query speed.
Snapshot Expiration and Orphan-File Cleanup
Iceberg's snapshot history is a feature, but left unmanaged it becomes a liability. Two maintenance tasks keep things healthy:
- Snapshot expiration. Removing old snapshots you no longer need for time travel, which also allows the underlying data files to be cleaned up.
- Orphan-file cleanup. Removing files that are no longer referenced by any snapshot—the debris left behind by failed writes and expired snapshots.
Neglecting these is one of the most common operational mistakes. Small files, stale snapshots, and orphan files accumulate silently until queries slow down and storage costs balloon.
Performance Tuning: Sort Orders, Z-Ordering, Write Distribution
Beyond compaction, a key tuning lever is write.distribution-mode. Misconfiguring it is a frequent cause of the small-file problem and can even trigger S3 503 throttling errors. Setting it to hash or range distributes writes more sensibly, producing fewer, better-sized files. Thoughtful sort orders and z-ordering further improve how efficiently engines can skip irrelevant data.
Observability and Cost Control
Because the lakehouse runs on metered cloud storage and compute, observability is directly tied to cost. Monitoring file counts, snapshot growth, table sizes, and query scan volumes lets you catch problems—like a table quietly accumulating small files—before they become expensive. In a well-run lakehouse, maintenance and monitoring are scheduled, automated, and treated as first-class operational concerns.
8. Migration Patterns
Most organizations don't start from scratch—they migrate from existing Hive and Parquet-based lakes.
In-Place vs. Shadow Migration from Hive/Parquet
There are two broad approaches:
- In-place migration adopts Iceberg metadata over existing data files where possible, avoiding a full data rewrite.
- Shadow migration creates new Iceberg tables alongside the originals and gradually moves workloads over.
The recommended posture is to migrate incrementally: create new tables in Iceberg while gradually converting existing Hive tables, rather than attempting a risky big-bang cutover.
Incremental and CDC Ingestion (Kafka/Flink → Iceberg)
A common modern pattern streams data into Iceberg in near real time. Apache Kafka carries events, Apache Flink performs CDC and writes governed Iceberg tables, and downstream consumers—Spark, Trino, ML pipelines—read from the same single copy of data. V3's row lineage and deletion vectors make this streaming-to-lakehouse pattern far more efficient than it used to be.
Multi-Engine Rollout
One of Iceberg's signature benefits is that many engines can operate on the same tables. A typical rollout might use Trino for dashboards, Spark for ETL, and PyIceberg for extracting training data—all against the same tables, governed by one catalog. This single-copy-of-data principle eliminates the copies, exports, and sync jobs that plagued earlier architectures.
9. The Lakehouse as AI Foundation
Serving Analytics, ML, and Agentic Workloads from One Copy
The lakehouse's open, single-copy design makes it a natural foundation for AI and machine learning. The same governed tables that power business intelligence can feed model training and AI workloads without duplicating data into separate systems. One copy, many consumers—including AI applications.
Storing Embeddings and Unstructured Data Alongside Tables
Increasingly, teams store vector embeddings and unstructured data alongside structured tables in the lakehouse. This co-location lets AI systems draw on both structured records and unstructured content through the same governed access layer, with Iceberg tables exposed to downstream applications through open APIs. Keeping structured and AI-ready data in one open store, under one catalog, is becoming a defining trait of the modern lakehouse.
10. The Road Ahead: Iceberg V4 and Format Convergence
Iceberg's momentum continues. V4 is in active design (not yet ratified), targeting single-file commits and faster, non-Avro metadata, with an eye toward real-time and streaming readiness. Describe it as forward-looking rather than shipped.
Two larger trends are worth watching:
- Format convergence. V3 deliberately aligns features—deletion vectors, row lineage, VARIANT—with Delta Lake. Combined with Databricks' UniForm and native Iceberg support, this points toward a future where the format you choose matters less than the catalog you choose.
- The catalog wars. Governance, federation, and metadata standardization across Polaris, Unity Catalog, and others are shaping up as the next major battleground. As format portability becomes a solved problem, the catalog becomes the strategic center of gravity.
Real-World Case Studies
The clearest evidence of Iceberg's maturity comes from organizations running it at extraordinary scale.
Salesforce Data Cloud scaled its open lakehouse to 4 million Iceberg tables and 50 petabytes, using Iceberg as the common format across Spark, Hyper, and Trino engines. It stores vector embeddings alongside structured data to power its Agentforce platform—a concrete example of the AI-foundation pattern in production (Salesforce Engineering blog).
Pinterest runs an approximately 500-petabyte S3 data lake with around 100,000 tables, 20,000+ Spark nodes, and 1,000+ Trino nodes. Principal Engineer Ashi Singh reported 65% cost savings on large joins and a 90x improvement in feature development speed using Iceberg storage-partition joins, plus a CDC framework that cut data-availability latency from over 24 hours to as little as 15 minutes (AWS re:Invent 2025 session STG211; Pinterest Engineering blog).
Netflix—Iceberg's birthplace, where it was created before being donated to the Apache Software Foundation—migrated an exabyte-scale lake of roughly 300 PB and 1.5 million Hive tables to Iceberg. It runs an "Autolift" service moving up to 3 petabytes daily, alongside an incremental-processing system that sharply reduced compute costs (AWS re:Invent 2023 session NFX306; Netflix TechBlog). (Note: the frequently cited ">80% compute cost reduction" figure circulates mainly through secondary summaries; the primary talk and engineering blog are the authoritative sources.)
Airbnb, after migrating its data-ingestion framework from Hive/TEZ to Spark 3 plus Iceberg, reported more than 50% compute resource savings and a 40% reduction in job elapsed time, processing 35 billion-plus Kafka events across 1,000+ tables daily (Airbnb Tech Blog, "Upgrading Data Warehouse Infrastructure at Airbnb").
Tools, Frameworks, and Platforms
The Iceberg ecosystem is broad. Key components worth knowing:
- Engines: Apache Spark, Trino/Presto, Apache Flink, DuckDB, Dremio, Snowflake, Amazon Athena/Redshift, Apache Doris, StarRocks.
- Catalogs: Apache Polaris, Databricks Unity Catalog (open source), AWS Glue Data Catalog, Project Nessie, Lakekeeper, Apache Gravitino.
- Managed/cloud: Amazon S3 Tables, Snowflake Open Catalog, Google BigQuery managed Iceberg, AWS SageMaker Lakehouse.
- Libraries: PyIceberg, iceberg-rust, iceberg-go.
- Ingestion and related: Apache Kafka, Apache XTable (cross-format conversion), Delta Lake UniForm, dbt, Airflow/Dagster.
Common Mistakes to Avoid
- Treating Iceberg as a database or engine rather than a table format that needs both a catalog and a compute engine.
- Skipping table maintenance—letting small files, stale snapshots, and orphan files accumulate until queries and costs balloon.
- Assuming V3 features work everywhere. Engine support is uneven; verify before adopting.
- Using non-Iceberg S3 operations to delete or overwrite files directly, which corrupts table state.
- Choosing a catalog without considering lock-in or multi-engine needs.
- Over-partitioning or partitioning on high-cardinality columns instead of using hidden partitioning sensibly.
- Misconfiguring
write.distribution-mode, producing too many small files.
Best Practices Checklist
- Separate concerns explicitly: pick the table format (Iceberg), then the catalog, then the engine(s).
- Standardize on the Iceberg REST catalog spec to preserve engine portability.
- Always run scheduled compaction, snapshot expiration, and orphan-file cleanup; on managed S3 Tables, verify automatic maintenance is enabled.
- Use sort or z-order compaction for tables with selective filter columns.
- Adopt V3 selectively—start with your highest-mutation and most semi-structured tables, after confirming engine support.
- Set
write.distribution-modeto hash or range to avoid the small-file problem and S3 throttling. - Mutate tables only through Iceberg-native APIs.
- Migrate incrementally rather than all at once.
How Iceberg Became the Standard
It's worth understanding why Iceberg won, because the consolidation happened recently enough to shape today's landscape. Industry commentary now describes Apache Iceberg as having effectively won the race to become the standard for the data lakehouse, driven by neutral Apache Software Foundation governance, broad multi-engine support, and a stable REST catalog API.
The defining moves all happened between 2024 and 2026:
- Databricks acquired Tabular, the startup founded by Iceberg's original creators (Ryan Blue and Daniel Weeks created Iceberg at Netflix and donated it to the ASF). The reported price ranged from "more than $1 billion" (per Databricks/TechTarget, June 2024) to "nearly $2 billion" (per Bloomberg via TechCrunch, August 2024) for a startup then doing roughly $1M in annual recurring revenue.
- Snowflake open-sourced the Polaris catalog and contributed it to the Apache Software Foundation.
- AWS shipped S3 Tables (fully managed Iceberg) to general availability in 2025.
- Databricks added native Iceberg support via Unity Catalog in June 2025.
When fierce competitors all standardize on the same open format, it signals a durable industry consensus rather than a passing trend.
The community signals reinforce this. The inaugural in-person Iceberg Summit drew nearly 500 community members to San Francisco on April 8, 2025, with speakers from AWS, Snowflake, Databricks, Microsoft, Cloudera, Apple, Airbnb, and Starburst. The apache/iceberg GitHub repository sits around 9,000 stars by mid-2026, with a brisk release cadence (versions 1.10.2 and 1.11.0 both shipped in May 2026).
A sourcing note: many adoption percentages and performance claims originate from vendors with commercial stakes—Databricks, Snowflake, Starburst, Dremio, and AWS. Treat specific figures as directional. The 74% CIO lakehouse statistic traces to MIT Technology Review Insights (2023).
Frequently Asked Questions
Is Apache Iceberg a database?
No. Iceberg is an open table format—a specification for how table metadata and data files are organized. It requires both a catalog (to track table state) and a compute engine (to run queries). Confusing it for a database is the single most common misconception.
What's the difference between a table format, a catalog, and an engine?
The format (Iceberg) defines how tables are structured. The catalog (Polaris, Unity, Glue, Nessie, Lakekeeper) tracks where each table's current metadata lives and manages atomic updates. The engine (Spark, Trino, Flink, DuckDB) reads and writes the data. You need all three.
Should I use V3 features right now?
Adopt V3 selectively. As of late 2025, engine support was uneven—Athena lacked V3 support, Trino/Presto were still implementing reader support, and PyIceberg offered only basic V3 reads. Confirm every engine in your stack supports the features you need before adopting, and treat any support matrix as a dated snapshot.
Managed or self-managed Iceberg—which should I choose?
Managed options like Amazon S3 Tables handle routine maintenance automatically and reduce operational risk, making them ideal for teams that want Iceberg's benefits without operating the machinery. Self-managed setups give you maximum control and can be more cost-efficient at scale, but require expertise in compaction, snapshot expiration, and tuning.
What is the small-file problem, and how do I fix it?
Frequent or streaming writes create many small files, which slow queries and raise costs. Fix it with scheduled compaction (using sort or z-order strategies for selectively filtered tables) and by setting write.distribution-mode to hash or range to produce fewer, better-sized files.
Can multiple engines use the same Iceberg tables?
Yes—this is one of Iceberg's defining strengths. A common setup uses Trino for dashboards, Spark for ETL, and PyIceberg for ML training extractions, all against the same tables governed by one catalog, with a single copy of the data.
What's coming in Iceberg V4?
V4 is in active design (not yet ratified). It targets single-file commits and faster, non-Avro metadata, with an emphasis on real-time and streaming readiness. Treat it as forward-looking rather than shipped.
Key Takeaways
- The lakehouse is the default. With 74% of CIOs already running one, the lakehouse is now the standard operating model—and Iceberg is its open interoperability layer.
- Master the three layers. Format (Iceberg), catalog, and engine are distinct. Internalizing this resolves most confusion.
- Metadata is the magic. Iceberg's metadata tree delivers ACID transactions, time travel, schema evolution, and hidden partitioning on cheap object storage.
- V3 adds real power, but verify support. Deletion vectors, row lineage, VARIANT, and geospatial types are genuinely useful—if your engines support them.
- The catalog is the decision that matters most. Format portability is nearly free; governance portability isn't. Standardize on the REST catalog spec to avoid lock-in.
- Operations are where value is won or lost. Compaction, snapshot expiration, orphan-file cleanup, and write-distribution tuning separate healthy lakehouses from expensive, slow ones.
- The future is catalog-centric and AI-ready. With V4 in design and formats converging, the next battleground is the catalog—and the lakehouse is becoming the foundation for AI workloads.
Sources
- MIT Technology Review Insights (2023) — 74% CIO lakehouse adoption figure
- 2025 State of the Apache Iceberg Ecosystem survey
- TechTarget (June 4, 2024) — Databricks/Tabular acquisition ("more than $1 billion")
- TechCrunch (August 14, 2024) — Bloomberg-reported "nearly $2 billion" acquisition figure
- Danica Fine, Snowflake Builders Blog — Iceberg Summit coverage (April 8, 2025)
- Apache Iceberg official documentation and table spec (iceberg.apache.org/spec)
- apache/iceberg GitHub repository, release notes, and V3/V4 spec discussions
- Apache Polaris (incubating) documentation
- AWS S3 Tables product documentation and AWS Prescriptive Guidance for Iceberg on S3
- Databricks and Google Open Source blogs on Iceberg V3
- PyIceberg and iceberg-rust documentation
- Salesforce Engineering blog — Data Cloud open lakehouse (4M tables, 50 PB)
- AWS re:Invent 2025 session STG211; Pinterest Engineering blog
- AWS re:Invent 2023 session NFX306; Netflix TechBlog
- Airbnb Tech Blog — "Upgrading Data Warehouse Infrastructure at Airbnb"
- Dremio — semi-structured ingestion and VARIANT
- Celerdata — multi-engine BI and ML
- U.S. Bureau of Labor Statistics — data scientist employment projections (36.0% growth, 2023–2033; median pay $108,020)